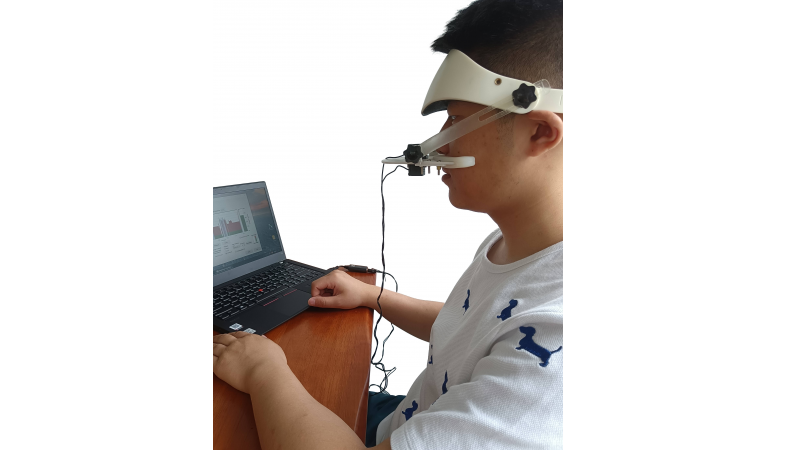
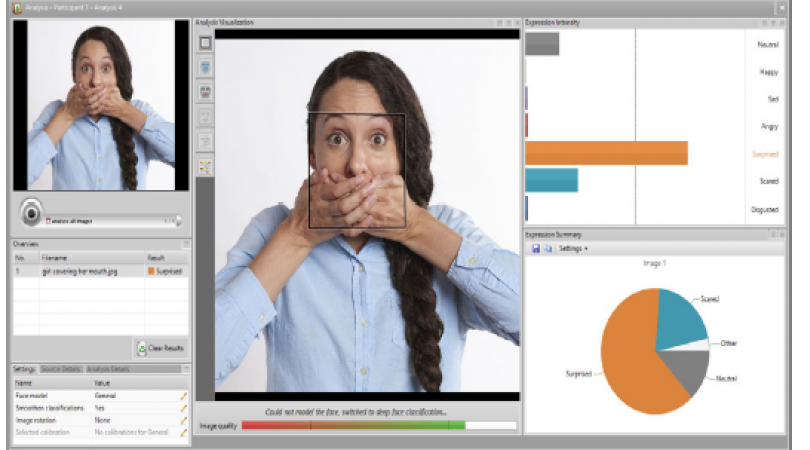
376 阅读 2020-09-17 09:26:02 上传
以下文章来源于 理论语言学与古汉语
Checklist
Q1 What does the phrase “middle road” literally mean? What does it mean in this specific context?
Q2 What is the subject of each sentence in Para.1? (Bracket the subject of each sentence)
Subject: (in grammar)
a noun, noun phrase or pronoun representing the person or thing that performs the action of the verb ( in ), about which sth is stated (the house in the house is very old ) or, in a passive sentence, that is affected by the action of the verb (the tree in the tree was blown down in the storm )
Q3 What are the connections between the subject of a sentence and the subject of the following sentence?
Q4 What is the predicate of each sentence in Para.1? (Bracket the predicate of each sentence)
Predicate: (in grammar)
the part of a sentence or clause that expresses what is said of the subject and that usually consists of a verb with or without objects, complements, or adverbial modifiers
Q5 What are the connections between the predicate of a sentence and the predicate of the following sentence?
Q6 Why is there a shift from the simple past tense to the simple present tense and then the simple past tense again? What can be the author’s communicative purposes?
Q 7 Why is there a shift from the active voice to the passive voice and then the active voice again? What can be the author’s communicative purposes?
Voice:
distinction of form or a system of inflections of a verb to indicate the relation of the subject of the verb to the action which the verb expresses active and passive voices
Q8 Who was/were talking in Para. 1, the Inductivists, the Eurekaists, or the author? If the author was just citing someone, was he positive, negative, or neutral about the ideas/theories cited? Find linguistic features in the paragraph to support your claim.
Homework of U4:
Step 1 Summarize the main idea of each paragraph;
Step 2 Highlight the key details of each paragraph;
Step 3 Identify the difficult words or sentences in each paragraph.
In-class Discussion of U4 for AEGS-22 in W12
Scoring Board:
CAO Yue 2;
XIONG Xinxuan 4;
XU Cheng 2;
YANG Yang 1;
TAO Junzhe 1;
LI Yulin 1;
TIAN Xiao 1;
ZHOU Jie 1;
DING Tonghsu 1;
YANG Guang 1;
Submission of Summary of U4 for AEGS-25 in W12
Scoring Board:
XU Cheng
ZHOU Mingjie
CHEN Leigang
CAO Yue
TAO Junzhe
XIONG Xinxuan
TIAN Xiao
LI Yulin
CHEN Leigang
LI Shasha
SUN Huayi
SUN Feier
YANG Yuguo
YANG Yang
Submission of Answer Sheet of Discussion about U4 by AEGS-22
Scoring Board:
MAI Jiaqian
FAN Taoyi
LI Huiyan
XU Xiaohe
WU Yungen
LI Mengxin
GE Linnan
ZHANG Yimeng
ZONG Leena
TIAN Mengmei
DONG Qianqian
DAN Wuran
JING Zhe
XU Ming
GAN Qinan
YE Xiaomeng
ZHANG Hongyu
FU Zhanglianxin
ZHANG Tianyi
WANG Hansheng
ZHANG Jun
Submission of Answer Sheet plus Sample Journal Article from ERPW-8 in W12
Scoring Board:
YANG Zhilong
HUANG Qiukai
TIAN Haochen
LIN Haitao
HUANG Shuqi
WU Chenwei
LIU Jian
BAO Zhen
WU Chenziwei
ZOU Minhao
HOU Funing
WANG Yunting
WAN Jun
YANG Zhipeng
Submission of Draft Introduction of Term Paper from ERPW-8 in W12
Scoring Board:
HOU Funing
LIN Haitao
YANG Zhilong
TIAN Haochen
WU Chenwei
HUANG Qiukai
WU Chenziwei
WANG Yunting
HUANG Shuqi
ZOU Minhao
LIU Jian
WAN Jun
YANG Zhipeng
BAO Zhen
Submission of Answer Sheet plus Sample Journal Article from ERPW-5 in W12
Scoring Board:
JIA Hecheng
CHU Zexuan
WANG Yalin
JI Zouhui
WU Wenya
LI Fei
ZUO Jingyi
DU Liang
PAN Xiang
TANG Shenqi
CHEN Ben
LI Qiang
XIANG Shitong
HUANG Lintao
Submission of Draft Introduction of Term Paper from ERPW-5 in W12
Scoring Board:
WANG Yalin
CHU Zexuan
DU Liang
WU Wenya
JI Zouhui
NIU Ben
PAN Xiang
JIA Hecheng
LI Fei
CHEN Ben
TANG Shenqi
LI Qiang
ZUO Jingyi
ZHANG Jun
XIANG Shitong
HUANG Lintao
Submission of Answer Sheet plus Sample Journal Article from ERPW-17 in W12
Scoring Board:
XUAN Piao
XU Tao
LIU Chang
DU Hongyi
SAI Linxi
HU Wennan
ZANG Jiaqi
WANG Xinhao
YUAN Hongbo
JIANG Jinhu
DONG Hui
JIANG Xiujie
LUO Jingda
LIN Haitao
WANG Chuanqing
HUANG Peng
XIE Chao
SHU Xiang
YI Bojuan
SHEN Kaijun
LI Yongwei
HUANG Guanhao
JIANG Qin
WANG Yingjie
SUN Nan
LI Yaopeng
LI Yue
ZHUANG Zi
Submission of Draft Introduction of Term Paper from ERPW-17 in W12
Scoring Board:
SAI Linxi
WANG Chuanqing
LIU Chang
YI Bojuan
JIANG Qin
WANG Xinhao
JIANG Jinhu
DU Hongyi
HU Wennan
SUN Nan
HUANG Peng
XUAN Piao
JIANG Xiujie
ZHUANG Zi
XU Tao
YUAN Hongbo
SHU Xiang
DONG Hui
SHEN Kaijun
TANG Yumei
LI Yongwei
WANG Yingjie
ZANG Jiaqi
LUO Jingda
LI Yue
A Systematic Review of Automatic Question Generation for Educational Purposes
https://link.springer.com/content/pdf/10.1007%2Fs40593-019-00186-y.pdf
Abstract
While exam-style questions are a fundamental educational tool serving a variety of purposes, manual construction of questions is a complex process that requires training, experience, and resources. This, in turn, hinders and slows down the use of educational activities (e.g. providing practice questions) and new advances (e.g. adaptive testing) that require a large pool of questions. To reduce the expenses asso-ciated with manual construction of questions and to satisfy the need for a continuous supply of new questions, automatic question generation (AQG) techniques were introduced. This review extends a previous review on AQG literature that has been published up to late 2014. It includes 93 papers that were between 2015 and early2019 and tackle the automatic generation of questions for educational purposes. The aims of this review are to: provide an overview of the AQG community and its activities, summarise the current trends and advances in AQG, highlight the changes that the area has undergone in the recent years, and suggest areas for improvement and future opportunities for AQG. Similar to what was found previously, there is little focus in the current literature on generating questions of controlled difficulty, enriching question forms and structures, automating template construction, improving presentation, and generating feedback. Our findings also suggest the need to further improve experimental reporting, harmonise evaluation metrics, and investigate other evaluation methods that are more feasible.
Keywords
Automatic question generation· Semantic Web· Education· Natural language processing· Natural language generation· Assessment· Difficulty prediction
Introduction
Exam-style questions are a fundamental educational tool serving a variety of pur-poses. In addition to their role as an assessment instrument, questions have the potential to influence student learning. According to Thalheimer (2003), some of the benefits of using questions are: 1) offering the opportunity to practice retrieving information from memory; 2) providing learners with feedback about their mis-conceptions; 3) focusing learners’ attention on the important learning material; 4)reinforcing learning by repeating core concepts; and 5) motivating learners to engage in learning activities (e.g. reading and discussing). Despite these benefits, manual question construction is a challenging task that requires training, experience, and resources. Several published analyses of real exam questions (mostly multiple choice questions (MCQs)) (Hansen and Dexter1997; Tarrant et al.2006; Hingorjo and Jaleel2012;Rushetal.2016) demonstrate their poor quality, which Tarrant et al. (2006)attributed to a lack of training in assessment development. This challenge is augumented further by the need to replace assessment questions consistently to ensure their validity, since their value will decrease or be lost after a few rounds of usage(due to being shared between test takers), as well as the rise of e-learning technologies, such as massive open online courses (MOOCs) and adaptive learning, which require a larger pool of questions.
Automatic question generation (AQG) techniques emerged as a solution to the challenges facing test developers in constructing a large number of good quality questions. AQG is concerned with the construction of algorithms for producing questions from knowledge sources, which can be either structured (e.g. knowledge bases (KBs)or unstructured (e.g. text)). As Alsubait (2015) discussed, research on AQG goes back to the 70’s. Nowadays, AQG is gaining further importance with the rise of MOOCs and other e-learning technologies (Qayyum and Zawacki-Richter2018; Gaebel et al.2014; Goldbach and Hamza-Lup2017).In what follows, we outline some potential benefits that one might expect from successful automatic generation of questions. AQG can reduce the cost (in terms of both money and effort) of question construction which, in turn, enables educators to spend more time on other important instructional activities. In addition to resource saving, having a large number of good-quality questions enables the enrichment of the teaching process with additional activities such as adaptive testing (Vie et al.2017), which aims to adapt learning to student knowledge and needs, as well as drill and practice exercises (Lim et al.2012). Finally, being able to automatically control question characteristics, such as question difficulty and cognitive level, can inform the construction of good quality tests with particular requirements. Although the focus of this review is education, the applications of question generation (QG) are not limited to education and assessment. Questions are also generated for other purposes, such as validation of knowledge bases, development of conversational agents, and development of question answering or machine reading comprehension systems, where questions are used for training and testing. This review extends a previous systematic review on AQG (Alsubait2015), which covers the literature up to the end of 2014. Given the large amount of research that has been published since Alsubait’s review was conducted (93 papers over a four year period compared to 81 papers over the preceding 45-year period), an extension of Alsubait’s review is reasonable at this stage. To capture the recent developments in the field, we review the literature on AQG from 2015 to early 2019. We take Alsubait’s review as a starting point and extend the methodology in a number of ways(e.g. additional review questions and exclusion criteria), as will be described in the sections titled “Review Objective” and “Review Method”. The contribution of this review is in providing researchers interested in the field with the following:1.a comprehensive summary of the recent AQG approaches;2. an analysis of the state of the field focusing on differences between the pre- andpost-2014 periods;3. a summary of challenges and future directions; and4.an extensive reference to the relevant literature.
Summary of Previous Reviews
There have been six published reviews on the AQG literature. The reviews reported by Le et al.2014, Kaur and Bathla2015, Alsubait2015and Rakangor and Gho-dasara (2015) cover the literature that has been published up to late 2014 while those reported by Ch and Saha (2018) and Papasalouros and Chatzigiannakou (2018) cover the literature that has been published up to late 2018. Out of these, the most comprehensive review is Alsubait’s, which includes 81 papers (65 distinct studies) that were identified using a systematic procedure. The other reviews were selective and only cover a small subset of the AQG literature. Of interest, due to it being a systematic review and due to the overlap in timing with our review, is the review developed by Ch and Saha (2018). However, their review is not as rigorous as ours, as theirs only focuses on automatic generation of MCQs using text as input. In addition, essential details about the review procedure, such as the search queries used for each electronic database and the resultant number of papers, are not reported. In addition, several related studies found in other reviews on AQG are not included.
Findings of Alsubait’s Review
In this section, we concentrate on summarising the main results of Alsubait’s systematic review, due to its being the only comprehensive review. We do so by elaborating on interesting trends and speculating about the reasons for those trends, as well as highlighting limitations observed in the AQG literature. Alsubait characterised AQG studies along the following dimensions: 1) purpose of generating questions, 2) domain, 3) knowledge sources, 4) generation method, 5) question type, 6) response format, and 7) evaluation. The results of the review and the most prevalent categories within each dimension are summarised in Table1. As can be seen in Table1, generating questions for a specific domain is more prevalent than generating domain-unspecific questions. The most investigated domain is language learning (20 studies), followed by mathematics and medicine (four studies each). Note that, for these three domains there are large standardised tests developed by professional organisations (e.g. Testof English as a Foreign Language (TOEFL), International English Language Testing System (IELTS) and Test of English for International Communication (TOEIC) for language, Scholastic Aptitude Test (SAT) for mathematics and board examinations for medicine). These tests require a continuous supply of new questions. We believe that this is one reason for the interest in generating questions for these domains. We also attribute the interest in the language learning domain to the ease of generating language questions, relative to questions belonging to other domains. Generating language questions is easier than generating other types of questions for two rea-sons: 1) the ease of adopting text from a variety of publicly available resources (e.g.a large number of general or specialised textual resources can be used for reading comprehension (RC)) and 2) the availability of natural language processing (NLP)tools for shallow understanding of text (e.g. part of speech (POS) tagging) with an acceptable performance, which is often sufficient for generating language questions.
…
Syntax-based approaches operate on the syntax of the input (e.g. syntactic tree of text) to generate questions. Semantic-based approaches operate on a deeper level (e.g.is-a or other semantic relations). Template-based approaches use templates consist-ing of fixed text and some placeholders that are populated from the input. Alsubait(2015) extended this classification to include two more categories: 4) rule-based and5) schema-based. The main characteristic of rule-based approaches, as defined by Alsubait (2015), is the use of rule-based knowledge sources to generate questions that assess understanding of the important rules of the domain. As this definition implies that these methods require a deep understanding (beyond syntactic understanding),we believe that this category falls under the semantic-based category. However, we define the rule-based approach differently, as will be seen below. Regarding the fifth category, according to Alsubait (2015), schemas are similar to templates but are more abstract. They provide a grouping of templates that represent variants of the same problem. We regard this distinction between template and schema as unclear. There-fore, we restrict our classification to the template-based category regardless of how abstract the templates are. In what follows, we extend and re-organise the classification proposed by Yaoet al. (2012) and extended by Alsubait (2015). This is due to our belief that there are two relevant dimensions that are not captured by the existing classification of different generation approaches: 1) the level of understanding of the input required by the generation approach and 2) the procedure for transforming the input into questions. We describe our new classification, characterise each category and give examples of features that we have used to place a method within these categories. Note that these categories are not mutually exclusive.
•Level of understanding–Syntactic: Syntax-based approaches leverage syntactic features of the input, such as POS or parse-tree dependency relations, to guide ques-tion generation. These approaches do not require understanding of the semantics of the input in use (i.e. entities and their meaning). For example, approaches that select distractors based on their POS are classified s syntax-based.
Semantic: Semantic-based approaches require a deeper understanding of the input, beyond lexical and syntactic understanding. The information that these approaches use are not necessarily explicit in the input(i.e. they may require reasoning to be extracted). In most cases, this requires the use of additional knowledge sources (e.g., taxonomies, ontologies, or other such sources). As an example, approaches that use either contextual similarity or feature-based similarity to select distractors are classified as being semantic-based.
•Procedure of transformation–Template: Questions are generated with the use of templates. Templates define the surface structure of the questions using fixed text and place-holders that are substituted with values to generate questions. Templates also specify the features of the entities (either syntactic, semantic, or both), that can replace the placeholders.–Rule: Questions are generated with the use of rules. Rules often accompany approaches using text as input. Typically, approaches utilizing rules annotate sentences with syntactic and/or semantic information. They then use these annotations to match the input to a pattern specified in the rules. These rules specify how to select a suitable question type (e.g. selecting suitable wh-words) and how to manipulate the input to construct questions (e.g. converting sentences into questions).–Statistical methods: This is where question transformation is learned from training data. For example, in Gao et al. (2018), question generation has been dealt with as a sequence-to-sequence prediction problem in which, given a segment of text (usually a sentence), the question generator forms a sequence of text representing a question (using the probabilities of co-occurrence that are learned from the training data).Training data has also been used in Kumar et al. (2015b) for predicting which word(s) in the input sentence is/are to be replaced by a gap (in gap-fill questions).Regarding the level of understanding, 60 papers rely on semantic information and only ten approaches rely only on syntactic information. All except three of the ten syntactic approaches (Das and Majumder2017; Kaur and Singh2017; Kusuma andAlhamri2018) tackle the generation of language questions. In addition, templates are more popular than rules and statistical methods, with 27 papers reporting the use of templates, compared to 16 and nine for rules and statistical methods, respectively. Each of these three approaches has its advantages and disadvantages. In terms of cost, all three approaches are considered expensive. Templates and rules require manual construction, while learning from data often requires a large amount of annotated data which is unavailable in many specific domains. Additionally, questions generated by rules and statistical methods are very similar to the input (e.g. sentences used for generation), while templates allow the generating of questions that differ from the surface structure of the input, in the use of words for example. However, questions generated from templates are limited in terms of their linguistic diversity.
….
Huang and He (2016) defined three characteristics for selecting sentences that are important for reading assessment and propose metrics for their measurement: keyness (containing the key meaning of the text), completeness (spreading over different paragraphs to ensure that test-takers grasp the text fully), and indepen-dence (covering different aspects of text content). Olney et al. (2017) selected sen-tences that: 1) are well connected to the discourse (same as completeness) and 2)contain specific discourse relations. Other researchers have focused on selecting topically important sentences. To that end, Kumar et al. (2015b) selected sentences that contain concepts and topics from an educational textbook, while Kumar et al.(2015a) and Majumder and Saha (2015) used topic modelling to identify topics and then rank sentences based on topic distribution. Park et al. (2018) took another approach by projecting the input document and sentences within it into the same n-dimensional vector space and then selecting sentences that are similar to the document, assuming that such sentences best express the topic or the essence of the document. Other approaches selected sentences by checking the occurrence of, or measuring the similarity to, a reference set of patterns under the assumption that these sentences convey similar information to sentences used to extract patterns (Majumder and Saha2015; Das and Majumder2017). Others(Shah et al.2017; Zhang and Takuma2015) filtered sentences that are insufficient on their own to make valid questions, such as sentences starting with discourse connectives (e.g. thus, also, so, etc.) as in Majumder and Saha (2015).Still other approaches to content selection are more specific and are informed by the type of question to be generated. For example, the purpose of the study reported in Susanti et al. (2015) is to generate “closest-in-meaning vocabularyquestions”9which involve selecting a text snippet from the Internet that contains the target word, while making sure that the word has the same sense in both the input and retrieved sentences. To this end, the retrieved text was scored on the basis of metrics such as the number of query words that appear in the text. With regard to content selection from structured knowledge bases, only one study focuses on this task. Rocha and Zucker (2018) used DBpedia to generate questions along with external ontologies; the ontologies describe educational standards according to which DBpedia content was selected for use in question generation.
….
The second most commonly employed method for evaluation is comparing machine-generated questions (or parts of questions) to human-authored ones (n = 15),which is carried out automatically or as part of the expert review. This comparison is utilised to confirm different aspects of question quality. Zhang and VanLehn (2016)evaluated their approach by counting the number of questions in common between those that are human- and machine-generated. The authors used this method under the assumption that humans are likely to ask deep questions about topics (i.e. questions of higher cognitive level). On this ground, the authors claimed that an overlap means the machine was able to mimic this in-depth questioning. Other researchers have compared machine-generated questions with human-authored reference questions using metrics borrowed from the fields of text summarisation (ROUGE (Lin2004)) and machine translation (BLEU (Papineni et al.2002) and METEOR (Baner-jee and Lavie2005)). These metrics measure the similarity between two questions generated from the same text segment or sentence. Put simply, this is achieved by counting matching n-grams in the gold-standard question to n-grams in the generated question with some focusing on recall (i.e. how much of the reference question is captured in the generated question) and others focusing on precision (i.e. how much of the generated question is relevant). METEOR also considers stemming and synonymy matching. Wang et al. (2018) claimed that these metrics can be used as initial, inexpensive, large-scale indicators of the fluency and relevancy of questions. Other researchers investigated whether machine-generated questions are indistinguishable from human-authored questions by mixing both types and asking experts about the source of each question (Chinkina and Meurers2017; Susanti et al.2015; Khodeiret al.2018). Some researchers evaluated their approaches by investigating the ability of the approach to assemble human-authored distractors. For example, Yaneva and et al. (2018) only focused on generating distractors given a question stem and key. However, given the published evidence of the poor quality of human-generated dis-tractors, additional checks need to be performed, such as the functionality of these distractors. Crowd-sourcing has also been used in ten of the studies. In eight of these, co-workers were employed to review questions while in the remaining three, they were employed to take mock tests. To assess the quality of their responses, Chinkina et al. (2017) included test questions to make sure that the co-workers understood the task and were able to distinguish low-quality from high-quality questions. However, including a process for validating the reliability of co-workers has been neglected inmost studies (or perhaps not reported). Another validation step that can be added to the experimental protocol is conducting a pilot to test the capability of co-workers for review. This can also be achieved by adding validated questions to the list of questions to be reviewed by the co-workers (given the availability of a validated question set).Similarly, students have been employed to review questions in nine studies and to take tests in a further ten. We attribute the low rate of question validation through testing with student cohorts to it being time-consuming and to the ethical issues involved in these experiments. Experimenters must ensure that these tests do not have an influence on students’ grades or motivations.
Publication Venues of AQG Papers
Journals1. Dialogue and Discourse32.
IEEE Transactions on Learning Technologies33.
Natural Language Engineering34.
Research and Practice in Technology Enhanced Learning3Conferences5.
Artificial Intelligence in Education76.
IEEE International Conference on Advanced Learning Technologies37.
International Conference on Intelligent Tutoring Systems38. IEEE International Conference on Cognitive Infocommunications29.
IEEE International Conference on Semantic Computing210.
IEEE International Conference on Tools with Artificial Intelligence211.
IEEE TENCON212.
The International Conference on Computer Supported Education213.
The International Joint Conference on Artificial Intelligence2
Workshops and other venues14.
The Workshop on Innovative Use of NLP for Building Educational Applications1215.
The Workshop on Building Educational Applications Using NLP416.
OWL: Experiences and Directions (OWLED)217.
The ACM Technical Symposium on Computer Science Education218.
The Workshop on Natural Language Processing Techniques for2
Educational Applications19.
The Workshop on Question Generation2